
Time series data and the human mind
Contents:
- The perceived race between artificial and human intelligence
- It all begins and ends with heuristics
- Like ships in the night - an informal meta-study of identification and prediction methods
- A rough classification of time series prediction approaches
- Gershenfeld and Weigend's comparison of a time-delay approach and a connectionist approach to the same problem
- The beauty of Takens' theorem
- The option of reparametrization
- Undressing the hype of brute-force AI
- Conclusion
The picture above shows the cockpit of an Airbus A380 airplane. Its layout is similar to that of the French A330 which due to 4 minutes and 23 seconds of pilot mishandling crashed into the Atlantic on June 1, 2009.
The cockpit layout has been designed to display to the pilots a compromise between clarity and the complexity necessary to take as many unexpected scenarios into account as possible. During those fatal minutes, the cockpit layout did not fullfill its purpose. Two design features apparently prevented the pilots from taking simple actions which could have saved the plane and put it back on track:
- The pilot in charge heard the sound of the "stall warning" only when he pushed his side-stick forwards. Being confused by what he probably perceived as erratic instrument readings (in fact, probably a maximum of two instruments failed at any time during those fatal minutes), he kept pulling his stick backwards even though that choice is today considered to be the only reason the plane crashed.
- The co-pilot tried to intervene by pulling his side-stick forwards. He may never have realized that this does not have the same effect on a side-stick that it has on a traditional yoke control. With a yoke, the pilots would have directly felt that they were fighting for the same control and might have come to grips with that fact in time.
This is, however, not an article about cockpit layouts or the psychology of human-machine interfaces. This article is about how to efficiently handle the abundant streams of time series data which form the basis of piloting as well as of other human endeavors indispensable to modern society.
On June 1, 2009, two human beings received as part of their job a multitude of data streams in real time. Severe flaws in just two of those streams triggered a fatal sequence of events during which pilot errors made a decisive contribution.
So, time series data play a crucial role in many high-tech applications. Humans need to understand those data.
The perceived race between artificial and human intelligence
A layman might observe: "an automatic algorithm would have solved the problem above". I - as another layman - observe that no Airbus control system has been redesigned as a consequence of the 2009 disaster.
During the years to come, I expect artificial intelligence to become increasingly visible in everyday life. However, I insist on seeing the much hyped singularity before I believe in its existence. I happen to consider my position healthier than - for instance - refusing to believe in man-made climate changes until their existence becomes indisputable.
As a 60 year old engineer paving my way in a world which will soon be taken over by younger people, I keep encountering the more or less explicitly stated assumption that "there is no reason to be overly meticulous with engineering knowledge or engineering data. Soon, artificial intelligence operating on fuzzy information will do way better."
I emphatically disagree.
It all begins and ends with heuristics
We are all driven by the hope of "doing better" in the future. However, such hopes are generally based on the simple fact that we do pretty well today. The events that we look back on in the evening will typically be the events that we anticipated the same morning. We accept that fact of life more than we understand it. During the day, however, we probably guided some events in the right direction through some decisions that we made.
We may think that we all the time based our decisions on a rigorous analysis of data. We may also in the evening examine such analyses in hindsight. However, these analyses will probably be different from the ones we did in real time.
Heuristic is the term for really not knowing what you are doing even though your choices tend to work. We do it all the time. Nobody should feel ashamed.
Like ships in the night - an informal meta-study of identification and prediction methods
A pervasive general trust in heuristics notwithstanding, digital computers have contributed immensely to the development of ways to predict the future from the past in terms of time series. Each individual algorithm developed during the last 75 years is typically based on a well-defined set of assumptions and constitutes a rigorous and scientifically based consequence of those assumptions. Thus, each of those advances is far from heuristic.
The funny thing is, however, that the entire collection of steps forward nevertheless appears unstructured and heuristic. I attribute that to an underlying, implicit selection mechanism: Only algorithms which produce useful results get published and are allowed to form the basis of future work. Through the years, many rigorous and scientifically based algorithms have probably been scrapped because they made useless predictions. The surviving algorithms are thus scientific and heuristic at the same time - "heuristic on a higher level", you might say.
With that in mind, I have stopped wondering why I recently encountered two monographs on time series analysis which present surprisingly disjoint information:
-
N. A. Gershenfeld and A. S. Weigend, "The Future of Time Series." In: Time Series Prediction: Forecasting the Future and Understanding the Past, A. S. Weigend and N. A. Gershenfeld, eds., 1–70. Addison-Wesley, 1993.
-
Karel J. Keesman, "System Identification - An Introduction", Springer-Verlag London, 2011.
If you go through the reference lists of these two monographs, you see only two common authors (H. Akaike and G.E.P. Box) and not a single common work. Gershenfeld and Weigend refer to seminal works by K. Gödel, A. Kolmogorov, F. Takens, A.M. Turing and V. Volterra, and Keesman refers to a seminal work by R.E. Kálmán.
A rough classification of time series prediction approaches
Even though the two monographs referred to above handle the overall subject very differently, they seem to agree concerning the relevance of these four approaches:
- Time-delay approaches. These work for linear time-invariant systems and are based on the assumption that during any small sub-period of the entire time-series, all observable values are related in a way which is independent of the sub-period chosen. Abbreviations like FIR, AR, MA, ARMA and ARMAX are abundant within approaches of this category. Formulations in the time domain, in the frequency domain or in the Laplace transform domain tend to end up the same place. This category may branch off to Generalized Linear Models.
- Nonlinear parametric approaches. Here, assumptions about the underlying physics lead to a model which in the general case (and then contrary to approach number 1 above) depend nonlinearly on some unknown parameters. These parameters may then be identified by iterative least-squares techniques.
- Hidden Markov Model approaches. This category may also be equivalent to approach number 1 above, but in the general case they belong to a class of their own. If you are interested in calculating the need for spare part replacements, the possibility of a damage parameter makes this approach particularly attractive.
- Connectionist approaches (also known as neural network or ANN approaches). This is the most modern approach, and for that reason it comes with both merit and hype. The remaining part of this article discusses how the pervasive quantity of ANN applications today should not mislead a mindful person into thinking that quantity is always accompanied by quality.
Gershenfeld and Weigend's comparison of a time-delay approach and a connectionist approach to the same problem
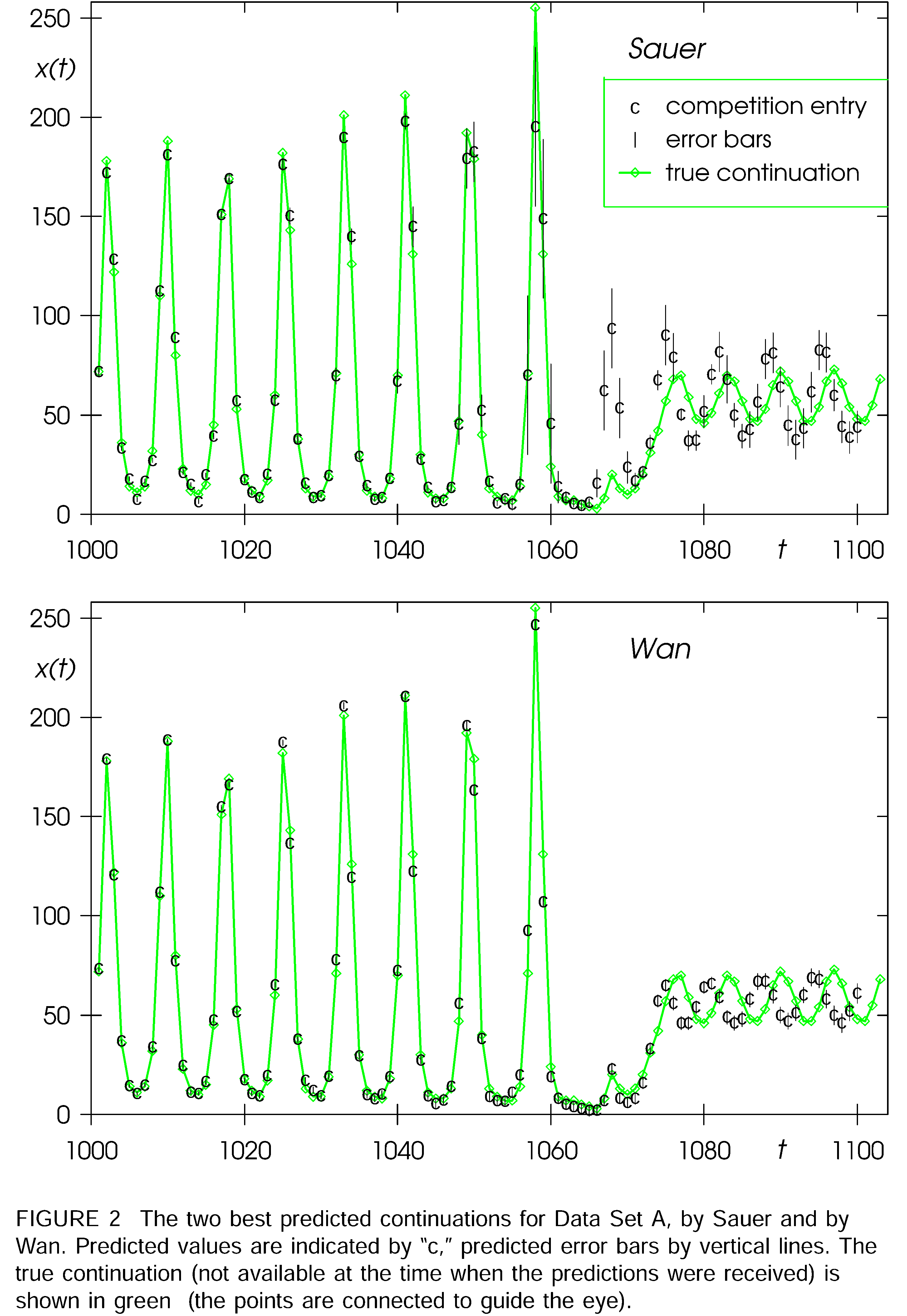
A most entertaining aspect of the work of Gershenfeld and Weigend is that they in 1990 announced a public competition between various takes on time series data predictions. They simply published the beginning of five different time series from five different scientific areas of interest. Then, they challenged the contestants to continue these time series without knowing the answer (which the authors kept secret).
The time series labeled "A" originated from the behavior of a far-infrared laser. In the present context it suffices to know that the time series came from a simple system of differential equations and was affected by only a modest amount of noise.
Allegedly, most responses to that challenge utterly failed. However, a time-delay solution by T. Sauer and a connectionist solution by E.A. Wan handled the main challenge very well: that the system at cutoff time was approaching a pole and would for that reason considerably change its behavior until leaving the pole again.
For the first 100 data points predicted by Sauer and Wan, the connectionist approach performed best (the green curve denotes "the right answer"):
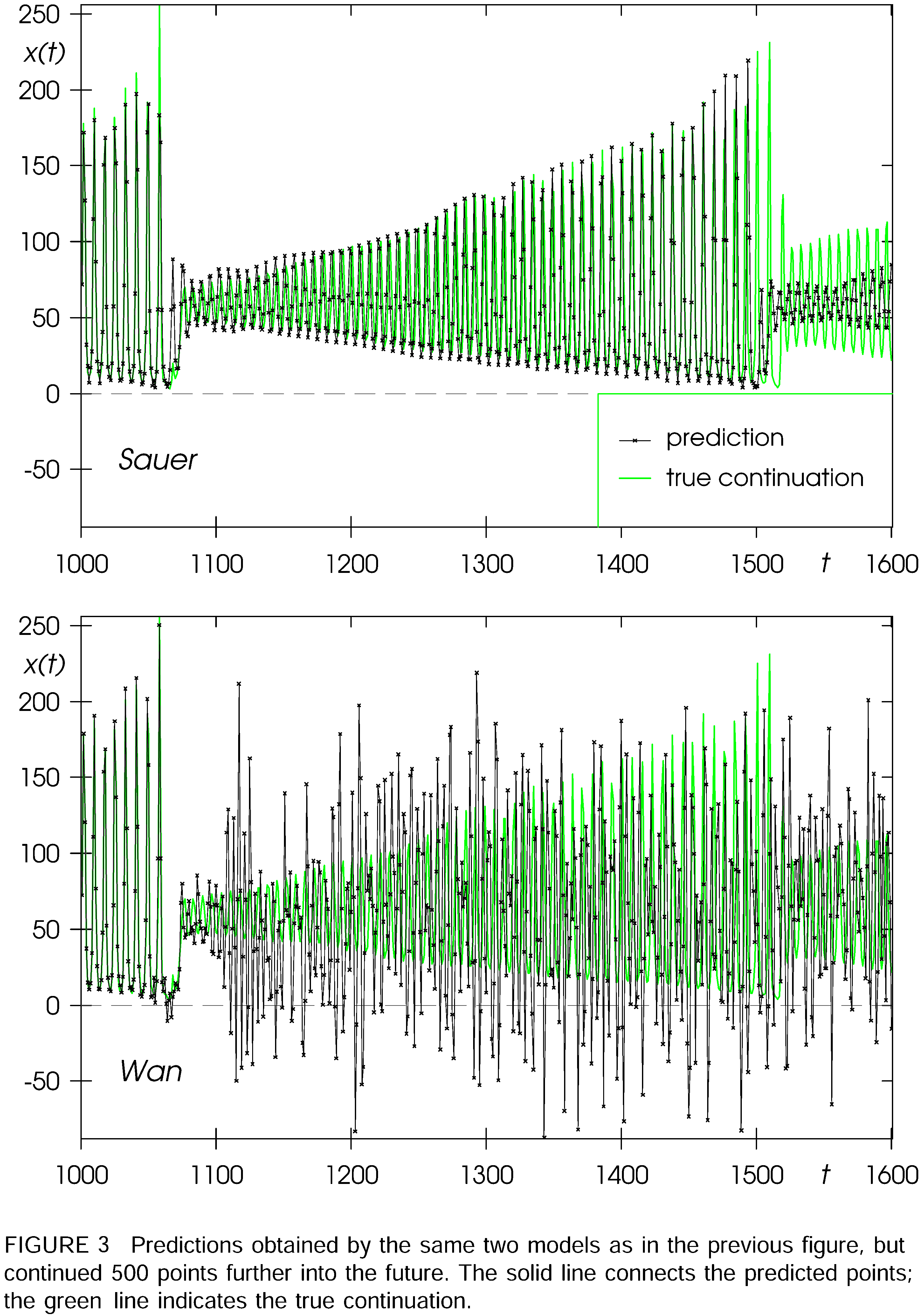
The "decisive victory" of the connectionist solution is, however, reversed when adding 500 additional unknown data points:
The beauty of Takens' theorem
In 1981, Floris Takens published the intriguing observation that if you study a physical phenomenon through a large number of observable variables (let's call that number N), you should expect intrinsic properties of real physical relations to have the consequence that only an M-dimensional subspace of N-dimensional space (M < N) is occupied by solution data.
Concerning the Gershenfeld and Weigend study leading to the previous two figures, Mr. Sauer, "the time-delay guy", was one of only a few people who discovered the limited dimensionality of the otherwise rather complex-looking appearance of time series "A". You may appreciate the suitably transformed "thin" or "surface-like" 2D appearance of a point cloud in 3D space below:
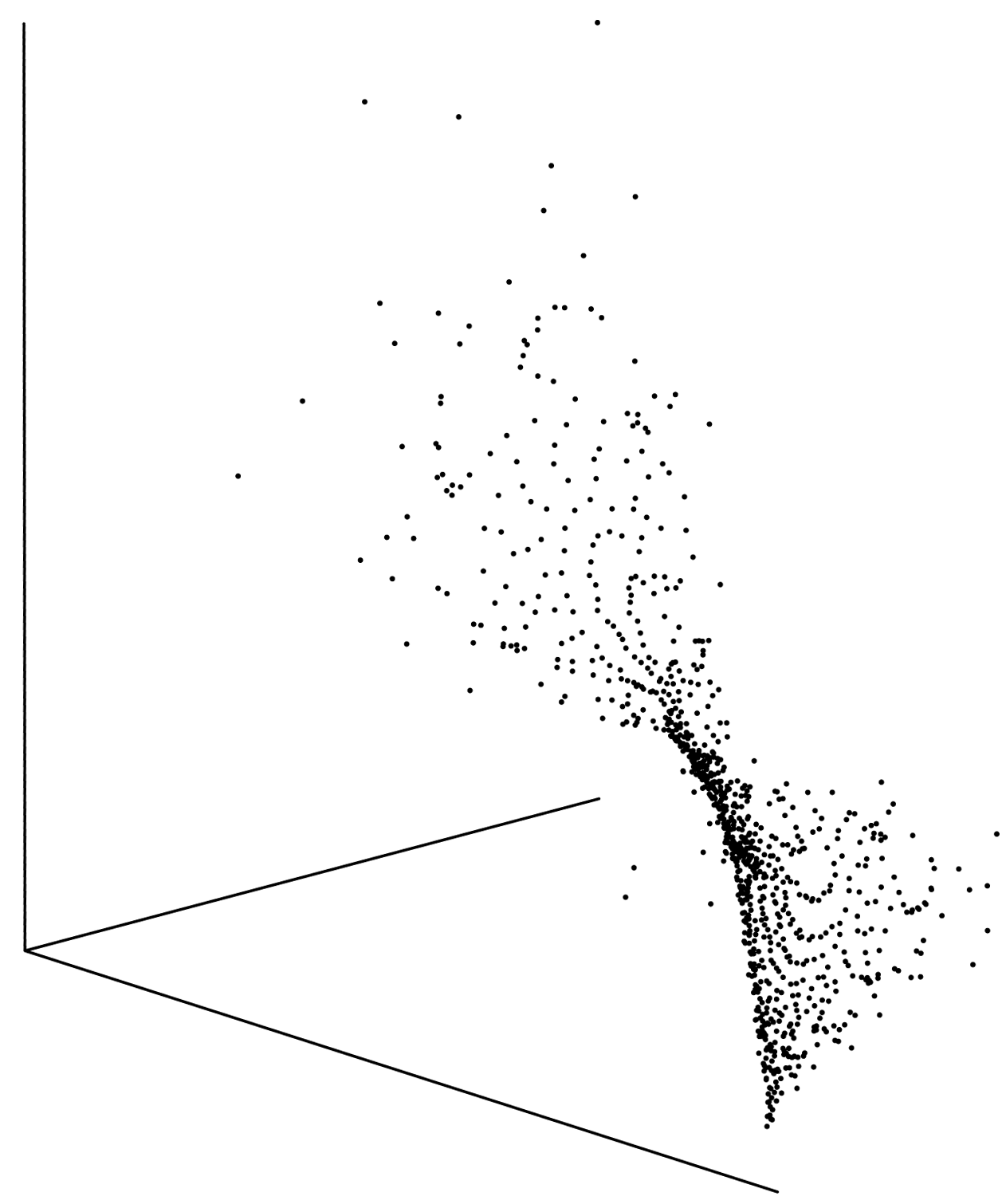
Concerning the Gershenfeld and Weigend competition, it appears to be a common trait that the winners had gone to great lengths in order to understand the inner structure of the data which they wanted to predict from. Brute force did not seem to pay.
The option of reparametrization
The human mind can hypothesize nonlinear parametric models much better than any automatic algorithm. On pages 157-158 in Keesman's monography, an elegant example shows how an assumed nonlinear behavior with respect to the unknown model parameters can be subjected to a parameter change which makes things much more linear and easier to handle. Quite unphysically, the parameter count increases by the change. Allegedly, the simplification due to reparametrization outweighs any adverse effect of overparametrization. A choice of the human mind which pays off...
Undressing the hype of brute-force AI
Thanks to Google and similar players on the consumer market, we are daily surrounded by overwhelming quantities of AI-generated data. I am, however, not at all impressed. An AI-based computer may win "Jeopardy", but AI fingerprints on my life have left me rather unaffected until now. For instance, some Google algorithms recently discovered that I was looking for a monography on system identification. For more than a week, Google advertisements suggested system identification books which I might be interested in buying. The algorithms correctly detected that I was looking for books about a certain subject. However, the algorithms never realized that
- I was looking for a monograph. By sheer definition, you only need one of those.
- I bought a monograph immediately after recognizing that I needed one.
This sequence of AI-based advertising events was entirely similar to the events some years ago when I needed a suitcase...
The most disturbing thing about trusting AI to assist you in your daily life is that you may end up concentrating on issues so mindless that off-the-shelf AI may be able to handle them (leaving, for instance, your love life in an unfortunate condition). One important presumption of most AI applications is that everything develops in a rather mainstream way. To predict bends on the road as efficiently as a mindful human, an AI algorithm must be highly tuned by a competent programmer.
Instead of following a mindless AI road, I find it worthwhile especially in my role as an engineer to focus on tasks that cannot be handled by AI. This article should provide ample evidence that the human mind still has a mission to accomplish if targets are to be succesfully reached or disasters are to be prevented.
This Czech course in system identification highlights a basic rule:

The above rule defines the exact opposite to a brute-force approach: Always take small and well-considered steps based on as much prior knowledge as possible. If you can package your knowledge into a clean, possibly machine-readable structure, then do so. Never expect knowledge to magically emerge from data whose quality you may not even be able to assess. AI processing based on noisy or otherwise information-depleted data may lead you anywhere without a single sign of warning.
In the context of mechanical engineering and/or scheduled maintenance issues, another observation applies: AI processing will only work on data of the past. Only a real life development engineer can tell you about the designs of the future and their mechanical properties.
Conclusion
Artificial Intelligence and Machine Learning will profoundly affect engineering disciplines during the years to come. However, they are not silver bullets. The need for the human mind to extract structure out of chaos will still be in demand. That goes for successful extrapolation of time series data as well as for many other aspects of life.
Watson, Google, Siri, whatever names you have been given: Your call...

